Using the SearchEngine class in ejScript
Note
Since this blog post was written, ejScript has been renamed CRMScript.
This blog post will give you an overview on how to use the SearchEngine class in ejscript. SearchEngine is probably one of the most commonly used ejScript classes.
The SearchEngine is one of the core-classes in ejScript, and has existed for a long time. Back in the day when Customer Service was still called Ejournal 4.x the SearchEngine would use T-SQL and ODBC to talk to the database. During the conversion from Ejournal 4.x to Customer Service 7.x the SearchEngine switched over to use the SuperOffice NetServer web services to read from and write to the database. This has a few advantages. SearchEngine no longer needs to worry about what type of database engine SuperOffice is running on. It doesn't really care if it is Oracle or MSSQL. One other advantage, which is important for consultants to know about, is that all queries that pass through the web services are subjected to various business rules in SuperOffice. For instance, the web services will make sure that all Sentry rules are respected, and will not give out information the user is not allowed to see.
But even if there are advantages to SearchEngine talking via the web services there are also some drawbacks. One is that NetServer (i.e. the web services) doesn't handle aggregated functions. So if you want to do a COUNT, SUM, MAX, etc then you need to bypass NetServer and use the old ODBC+SQL approach. This is simple to do, and you'll see how it works a bit further down.
For now, let's do a simple query. When you play around with ejScript it is easy to just go to System Design>Script, and create a temporary script there. You can test it immediately by using the Execute script button.
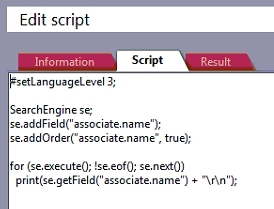
This query corresponds to the T-SQL statement:
SELECT name FROM crm7.associate ORDER BY name ASC
Here we first create a SearchEngine named se. Next, we tell it to query the crm7.associate table for the name field. The addOrder(string, bool) is used to sort the list alphabetically.
Then, in a for-loop we call se.execute() to run the actual query. That will perform the search, and populate the SearchEngine with the result. The for-loop will then call se.next() for each result until se.eof() (end-of-file) is reached. For each result, we call print() to write the found value to the screen.
As a new-line character I print out "\r\n". Alternatively, if you've checked the Show result of runing script as HTML checkbox you can print <br /> to get a newline.
Usually, when you do a search, you also want to filter the values. Let's say we only want the associates that have a corresponding ejuser.

Here we add a line with .addCriteria(string, string, string, string, int). The first variable is the field we want to filter on, the second is the type of operator, and the third is the value.
The operators you can use as the second variable are:
- OperatorEquals
- OperatorGte
- OperatorNotEquals
- OperatorLt
- OperatorLte
- OperatorGt
- OperatorGte
- OperatorLike
- OperatorNotLike
- OperatorContains
- OperatorBeginsWith
- OperatorEndsWith
- OperatorIn
- OperatorNotIn
- OperatorIs
- OperatorOracleLeftJoin
- OperatorIsNot
The fourth and fifth variables are used when you have more than one .addCriteria call and are used to control how you wrap the parentheses and AND/OR between each criterion. The fourth operator can be either OperatorAnd, OperatorOr, OperatorNotAnd, or OperatorNotOr.
One neat feature with the SearchEngine is the so-called dot-syntax. It refers to the fact that we can use dots to join tables. Here is an example where we search for all contacts with a given category and use the dot-syntax to display the full name of the Our Contact.
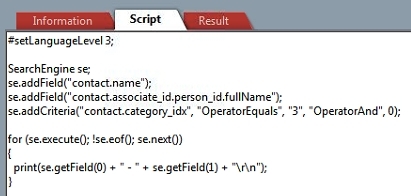
Notice here the way we use contact.associate_id.person_id.fullName to "dot" our way from the contact table via the associate table over to the person table. The keen observer will notice that I'm displaying a field called fullName, even if there is no such field in the physical database. This is because there are a few "virtual fields" that we can use. fullname, emailAddress, and direct/formattedNumber are a few examples of these fields.
In T-SQL there is a TOP operator, which is used to limit the number of rows returned, and SearchEngine has a method for this as well. If you want to limit the number of rows you can call se.setLimit(15)
In T-SQL you also have the DISTINCT keyword. This actually has two corresponding methods: .setDBDistinct(bool) and .setDistinct(string).
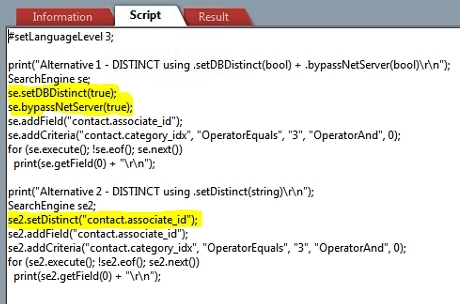
These will give the same result, but notice that when using .setDBDistinct(true) you also need to set .bypassNetServer(true) for it to have any effect.
If you want to use any aggregated functions like COUNT, SUM, or AVG then you need to use .bypassNetServer(true) since the NetServer web services do not support this. If you forget you'll get an error saying
Original exception: NetServerException: Can't use field functions when querying NetServer
For .bypassNetServer(true) to be allowed to be used on the database you need to enable it in the crm7.registry table with this:
UPDATE crm7.registry SET value = 1 WHERE reg_id = 235
Here is an example calculating the average amount on open sales for each associate:
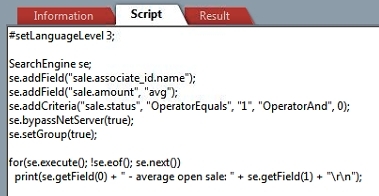
Notice how we use two variables on the second call to .addField(string, string). The second variable is the function name. And since we use an aggregated function we also need to add the GROUP BY statements using se.setGroup(true).
Maybe you've noticed that in all the examples above I've used se.getField(0) and se.getField(1) when retrieving the values found. The numbers correspond to the order the .addField() methods have been added. A better way is actually to not use numbers, but rather use the full field name instead. It does add a bit more text to your script but is probably easier to maintain than using the index numbers.

In addition to searching for data, you can also use the SearchEngine class to write data to the database. Best-practice is actually to use the NetServer agent classes for writing to the database, but it is often convenient to use a SearchEngine instead.
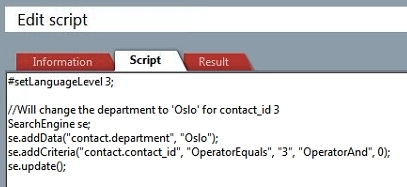
Here we use se.addData to indicate where and what we want to write to the database. And since we don't want to make the same change to every row in the table we use addCriteria() to ensure we only change one row. Finally, we call se.update() to perform the update.
Note
Writing to the database this way does not log the change to the crm7.traveltransactionlog table, and should therefore be avoided in environments with satellites and travelusers.
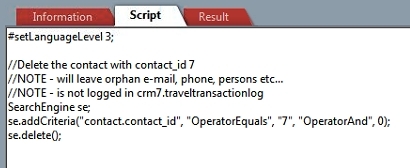
Here is an example of how to delete something from the database. Again - best-practice is to use the NetServer agent classes to remove data since they also remove data from related tables and log changes to the traveltransactionlog.
Even though all the examples above have been written in System Design>Scripts this doesn't mean that this is the only place you use SearchEngine. Most often it is used in a custom screen. Either in one of the load events or in the creation script for one of the elements on the screen. I'll leave you with an example where I have added a Listbox to a custom screen, and use a SearchEngine to fill it with items.
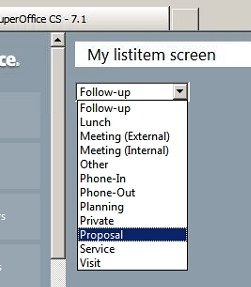
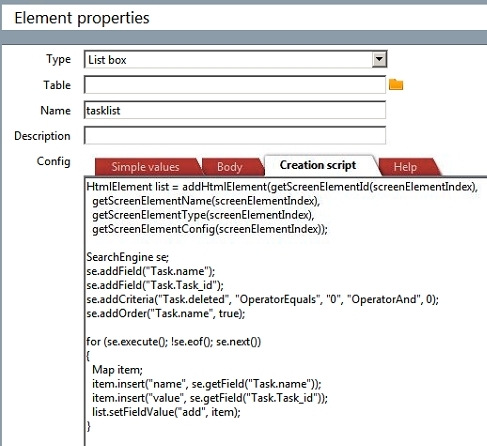
Oh, and one final thing. Notice how I've capitalized the T in the table Task? The table- and field names you give the SearchEngine must match the same casing as is used in the crm7.conceptualtable and crm7.conceptualfield tables. Most of them are just lowercase, but there are a few that start with a capital letter.
This has been a walk-through of some of the most common usages of the SearchEngine class. The SearchEngine has lots of other methods that I haven't covered here, so feel free to explore the documentation linked at the top of the blog post.
Good luck!